
Nel corso degli ultimi mesi abbiamo pubblicato diverse guide su come utilizzare servizi alternativi a quelli di Google che siano open source e privi di tracciamenti indesiderati. Nonostante non consigliamo affatto l’uso di Chrome (meglio Bromite in questo senso), è innegabile il fatto che Google abbia investito molto nella sicurezza dei propri utenti attraverso alcune tecnologia all’avanguardia. A questo proposito, vi vogliamo spiegare cos’è il Safe Browsing di Google Chrome (da un po’ disponibile per tutte le app Android) e come funziona.
La maggior parte di noi dovrebbe avere familiarità con la funzione Safe Browsing di Chrome, che avverte se si sta visitando una pagina che potrebbe essere pericolosa. Non è che la maggior parte di noi stia attivamente cercando malware o siti di phishing, ma di tanto in tanto, alcuni link sui social media, un’e-mail o qualche suggerimento ci portano in un posto sgradevole e Chrome fa sapere che potrebbe non essere una buona idea per procedere.
Probabilmente non ci abbiamo mai pensato molto a fondo, ma inizialmente credevamo che il sistema funzionasse perché Google sapeva, tramite Chrome, quali pagine stavamo visitando e le teneva d’occhio in base a un elenco. Questo è in parte vero, ma sfugge a un fatto critico e interessante: il sistema Safe Browsing in realtà non dice a Google su quali pagine ci troviamo, il che serve a preservare un po’ di più la privacy (per quanto possibile con un’azienda che vive letteralmente grazie alla raccolta dati sui propri utenti).
Safe Browsing di Chrome dunque non trasmette ai server di Google un elenco continuo degli URL che visiti. Infatti, secondo un post sul blog pubblicato di recente che descrive le API e i sistemi utilizzati, Chrome mantiene un elenco locale sul dispositivo con cui confrontarlo.
Ma questo non è solo un elenco di URL. Per quanto intuitivo possa sembrare, diventerebbe rapidamente un qualcosa ad elevato consumo di spazio di archiviazione e di risorse: Google ci sta proteggendo da più pagine di quanto potreste pensare. Invece, lo smartphone o il computer mantiene un elenco di cosiddetti “hash”, che sono stringhe semi-univoche di lettere e numeri generate crittograficamente e create da ciascun URL univoco.
Google ha messo in atto soluzioni alternative per la logica alla base del funzionamento di questo sistema per garantire che una leggera modifica nell’URL non aggiri facilmente la sicurezza, quindi modifiche casuali al sottodominio o alle sottopagine non consentiranno agli hacker di apportare lievi modifiche che sfuggono al rilevamento.
Gli elenchi vengono inoltre aggiornati ogni trenta minuti circa. Inoltre, anche gli hash completi renderebbero un elenco troppo grande oltre un punto, quindi Google in realtà memorizza solo i primi quattro bit troncati degli hash. Sono ancora sufficienti dati univoci affinché la maggior parte degli URL sicuri non vengano catturati accidentalmente, ma alcuni lo faranno comunque: i non informatici dovrebbero notare che quattro bit sono sufficienti per memorizzare fino a 4,29 miliardi di identificatori univoci, ma puoi comunque incappare in “collisioni ” dove due pagine univoche possono effettivamente generare lo stesso hash per quella lunghezza di bit. Questo è problematico, in quanto può significare che due pagine diverse generano lo stesso hash in questo sistema, il che significa che Chrome potrebbe riconoscere una pagina buona come potenzialmente nota come cattiva.
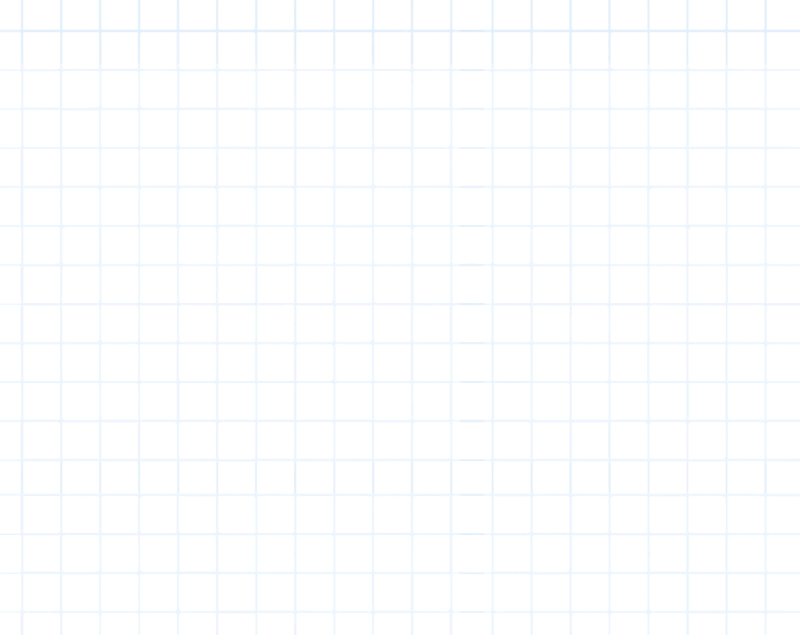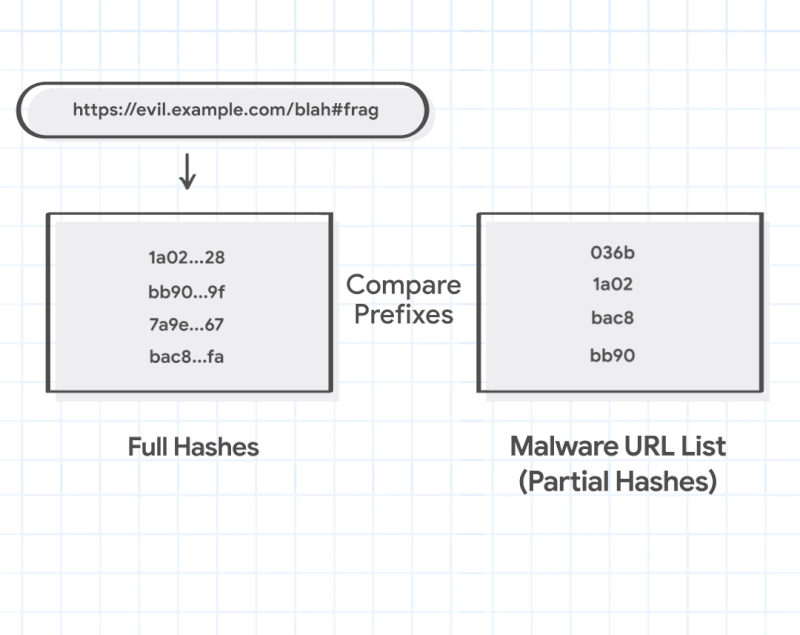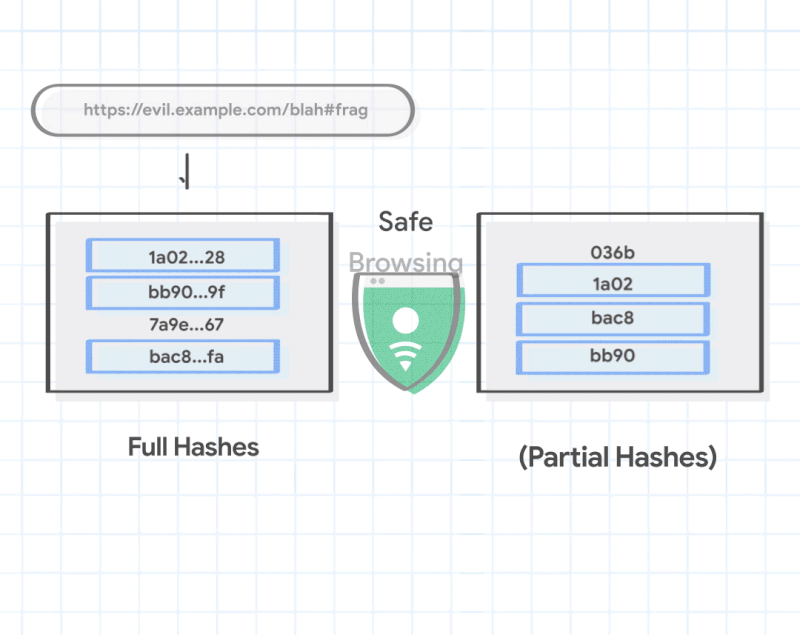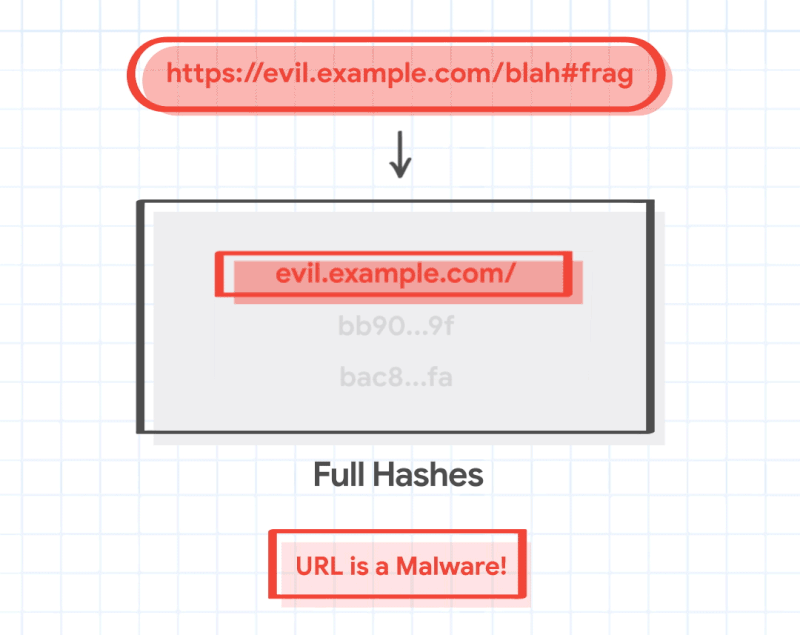
Attualmente ci sono oltre 1,88 miliardi di siti Web e anche le vecchie stime collocano il numero di pagine uniche indicizzate da Google a trilioni, quindi Safe Browsing è destinata a produrre alcuni falsi positivi se utilizza solo questo sistema. Per fortuna, c’è un altro passaggio.
Quando Google scopre che un hash parziale di una pagina corrisponde agli elenchi di hash parziali corrispondenti per malware o adware o altro, Chrome chiede a Google tutti gli URL che corrispondono a quell’hash parziale, in modo da poter effettuare un confronto locale. Ciò significa che il browser è quindi in grado di effettuare una seconda chiamata di giudizio localmente dove Google non può vederlo, confrontando un identificatore hash molto più lungo per il sito che si sta visitando con l’elenco molto più grande di Google.
Ciò significa anche che i server e le API di Google che si occupano di questa funzione di navigazione sicura in realtà non sanno esattamente in quale pagina ci si trova: il confronto avviene sul dispositivo.


