
L’esecuzione di modelli linguistici di grandi dimensioni (LLM) a livello locale può essere estremamente utile, sia che tu voglia provare e testare gli LLM o integrarli in delle app. Ma configurare il tuo ambiente di lavoro e far funzionare i LLM sul tuo computer non è banale. Quindi, come è possibile eseguire LLM localmente senza problemi? È qui che entra in gioco Ollama, una piattaforma che rende lo sviluppo locale con modelli linguistici di grandi dimensioni open source un gioco da ragazzi.
Ollama è uno strumento basato su riga di comando (esistono strumenti per avere una UI semplice e piacevole in stile ChatGPT) per il download e l’esecuzione di LLM open source come Llama 3, Phi-3, Mistral, Google Gemma e altri. Semplifica la gestione i pesi dei modelli, le configurazioni e i set di dati in un unico pacchetto controllato da un Modelfile. Tutto quello che devi fare è eseguire alcuni comandi per installare i LLM open source supportati sul tuo sistema e utilizzarli.
Ollama stesso è open source e consente una perfetta integrazione con un modello linguistico localmente o dal tuo server. Ollama funziona perfettamente su Windows, Mac e Linux. Chiaramente, in base al modello LLM che si sceglie, necessita di una potenza hardware differente (i modelli da 7B possono essere eseguito anche con una iGPU AMD 780M e 8 GB di RAM).
Scaricare Ollama
Come primo passo, devi scaricare Ollama sul tuo computer.
Per eseguire il download, puoi visitare il repository GitHub ufficiale e seguire i collegamenti per il download. Oppure visita il sito Web ufficiale e scarica il programma di installazione se utilizzi un computer Mac o Windows. In alternativa, su Linux puoi usare il terminale e digitare il seguente comando:
curl -fsSL https://ollama.com/install.sh | shIl processo di installazione richiede in genere alcuni minuti. Durante il processo di installazione, qualsiasi GPU NVIDIA/AMD verrà rilevata automaticamente, così come le NPU ufficialmente supportate nei processori Intel e AMD.
Scaricare e usare i modelli LLM
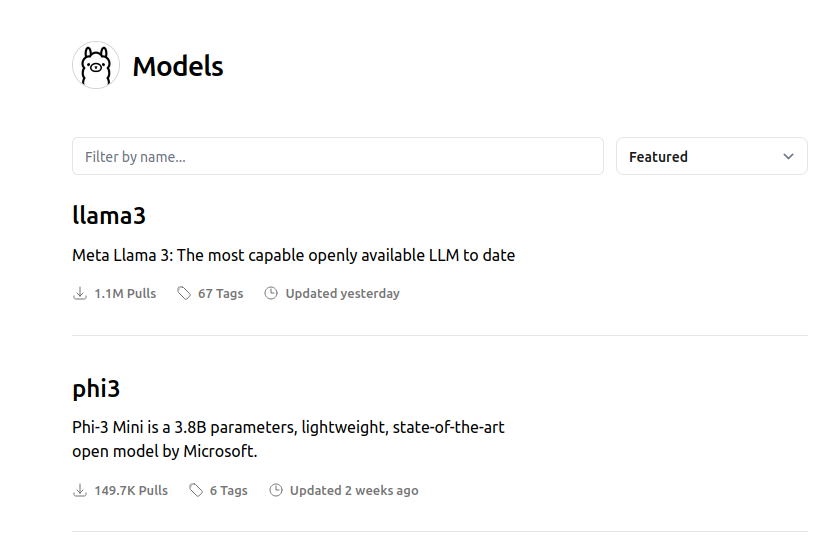
Successivamente, puoi visitare la libreria dei modelli per controllare l’elenco di tutti gli LLM attualmente supportati. Il modello predefinito scaricato è quello con il tag latest. Nella pagina di ciascun modello è possibile ottenere maggiori informazioni come la dimensione e la quantizzazione utilizzata.
Puoi cercare nell’elenco dei tag per individuare il modello che desideri eseguire. Per ciascuna famiglia di modelli, in genere esistono modelli fondamentali di diverse dimensioni e varianti ottimizzate per le istruzioni. Uno dei modelli più popolari scaricati in questo momento è Llama 3 di Meta.
Per scaricare effettivamente il modello, devi aprire il terminale (CMD su Windows) ed eseguirlo utilizzando il comando ollama run "nomemodello". La prima volta che lo esegui verrà inizializzato il download prima di poter iniziare a interagire direttamente con il modello.
| Modelli | Parametri | Dimensioni | Comando |
|---|---|---|---|
| Llama 3 | 8B | 4.7GB | ollama run llama3 |
| Llama 3 | 70B | 40GB | ollama run llama3:70b |
| Phi-3 | 3.8B | 2.3GB | ollama run phi3 |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Gemma | 2B | 1.4GB | ollama run gemma:2b |
| Gemma | 7B | 4.8GB | ollama run gemma:7b |
| Solar | 10.7B | 6.1GB | ollama run solar |
L’utilizzo base avviene attraverso il terminale. Basta digitare il prompt e attendere che il modello LLM dia una risposta.
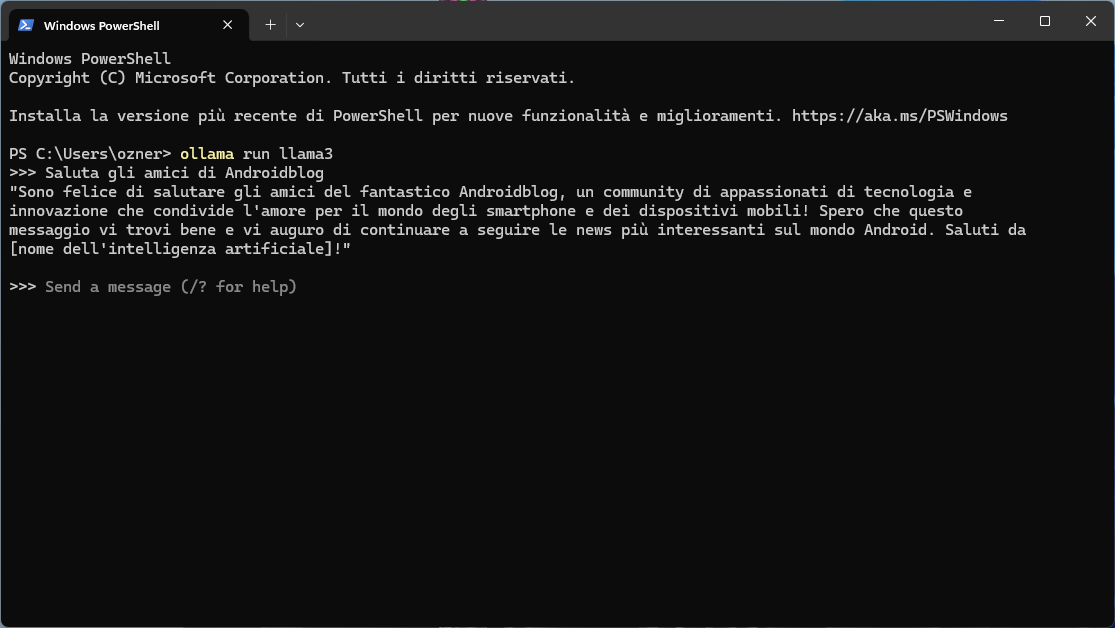
In quest’altra guida approfondita vi mostro come utilizzare un server web per eliminare la necessità del terminale e sfruttare una UI molto semplice e pulita derivata da quella di ChatGPT.


